User survey 2022#
We have published the results of our yearly user survey, conducted in February 2022. Feedback from users’ experiences in Hydra adds valuable insight into their needs, what works well, and what needs further improvement.
We counted 153 active VUB Hydra users in 2021 (i.e. submitted at least one job). We received 51 survey responses (at least one question answered), representing 33% of our user base. For ease of comparison, we’ve kept most questions identical to last year’s survey. This year we have also included a few questions regarding “the big item of 2021” - the switch from Torque/Moab to the Slurm workload manager.
If you have any questions or comments, feel free to contact us at VUB-HPC Support.
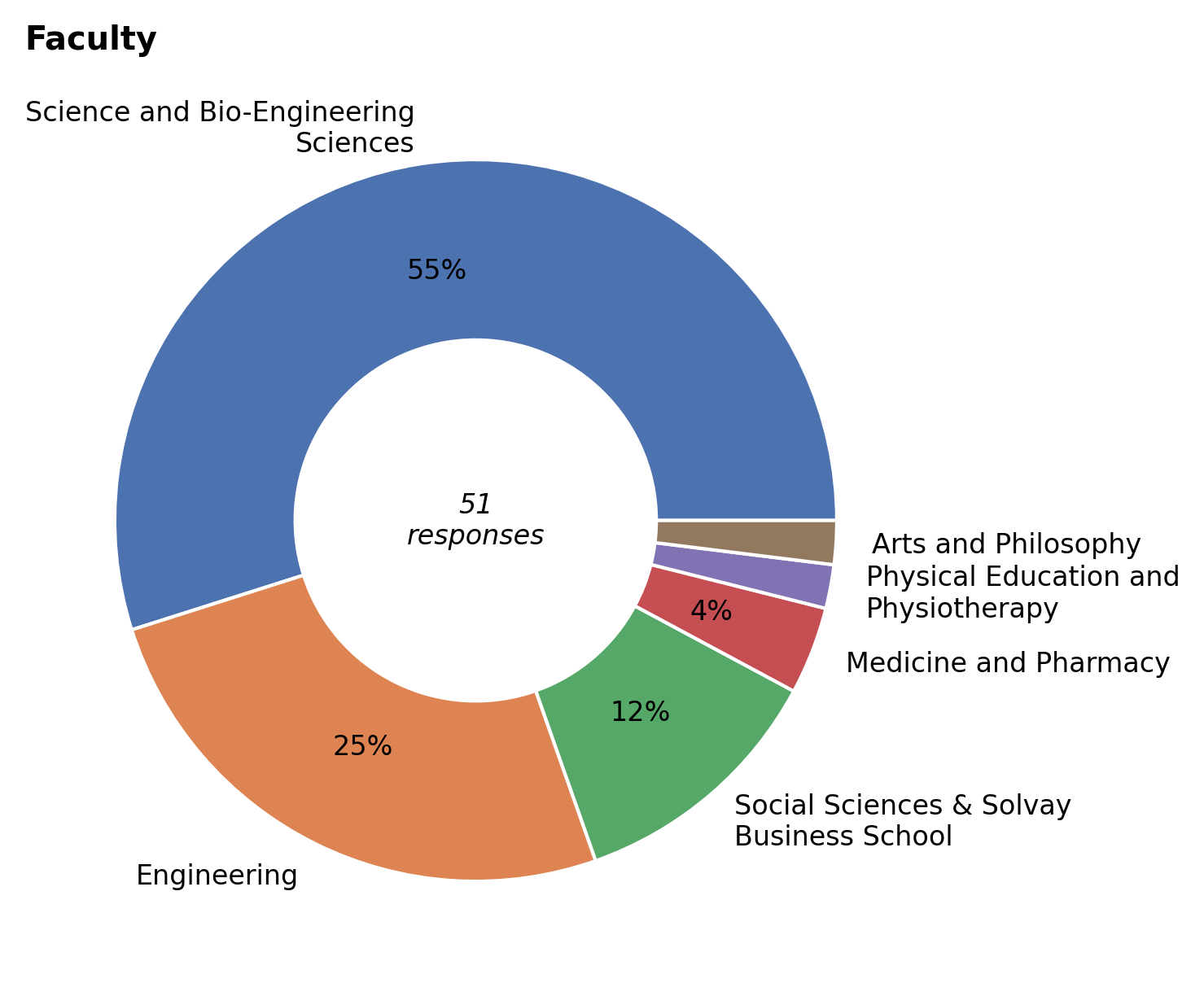
Faculty#
Respondents belong to one of five VUB faculties. Similar to last year, most of them are from the traditionally strongly represented Sciences and Engineering departments, with Social Sciences and Solvay Business School, and Medicine and Pharmacy coming in third and fourth. Notable faculties not yet represented are:
Law and Criminology
UZ Brussel
Vesalius College
We will continue our efforts to make Hydra better known to research groups that are less familiar with the potential applications of the HPC in their research. We’re also working on a web interface for easier access to the HPC infrastructure, and also provide Jupyter notebooks to our users. This new portal will make Hydra more easily accessible to all researchers, including those who are less IT-minded.
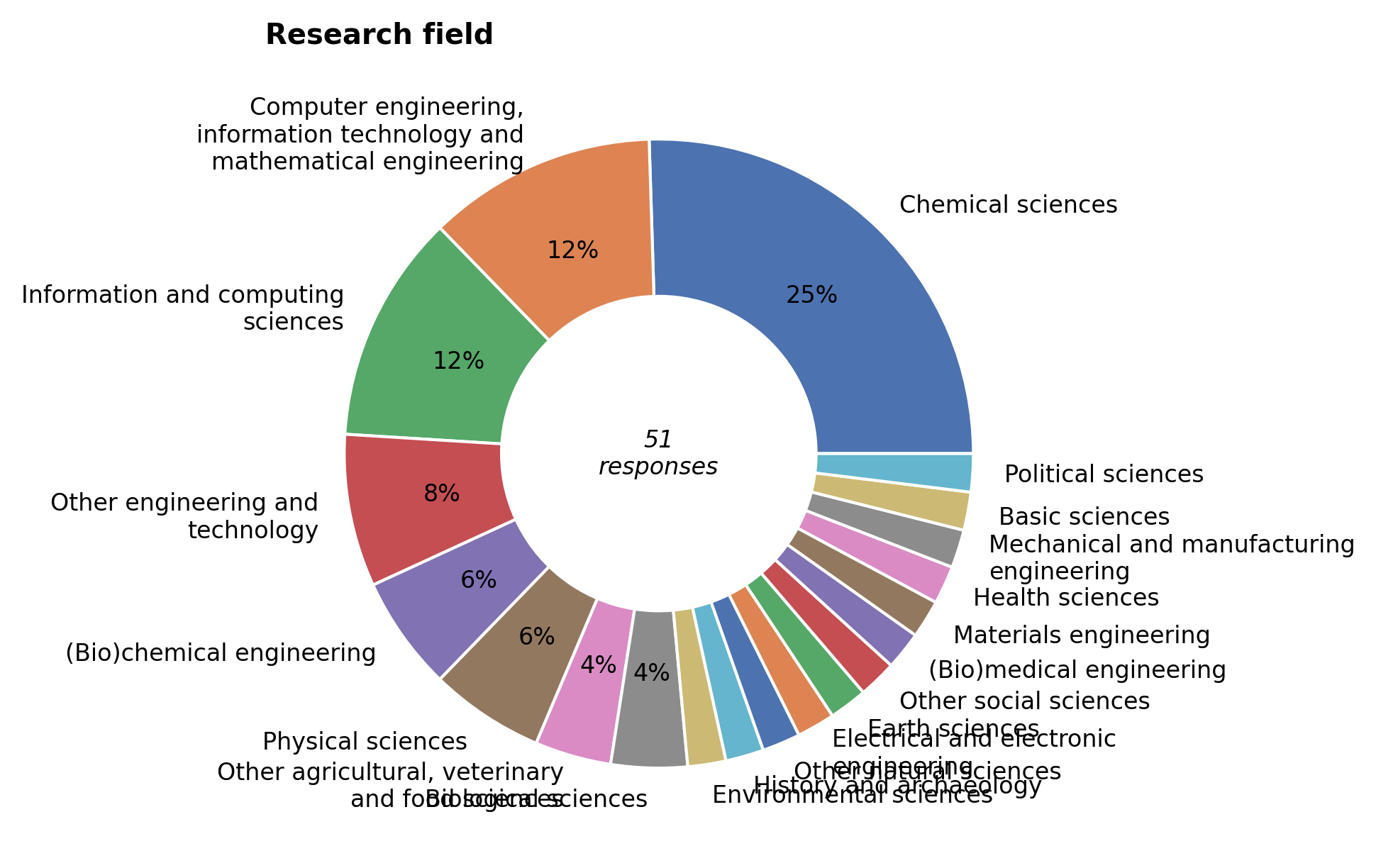
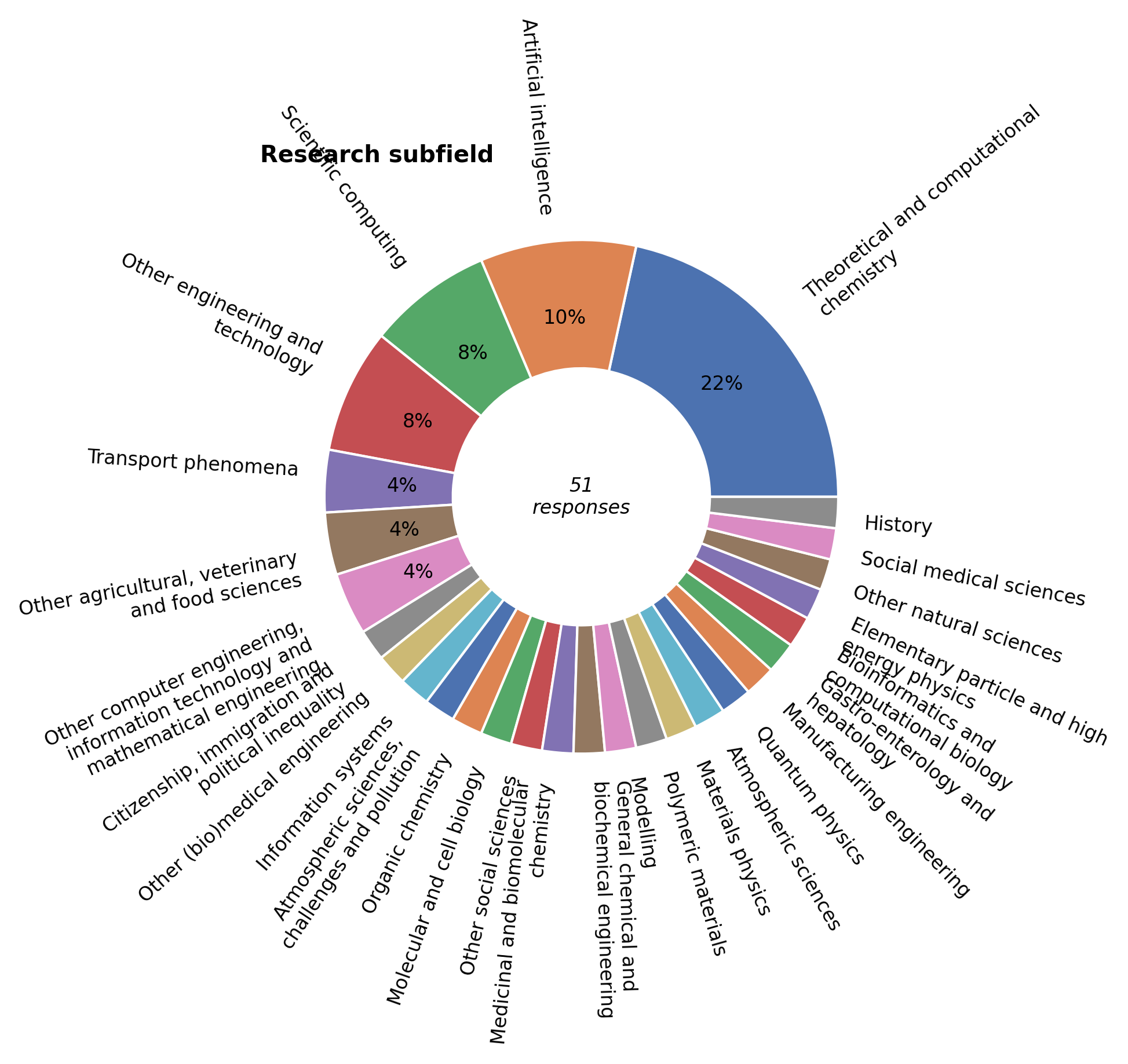
Research field#
Hydra serves researchers from a wide range of fields and sub-fields. Computational Chemistry stays comfortably at the top. This year, however, Artificial Intelligence has conquered the number two spot, followed by the general field of Scientific Computing.
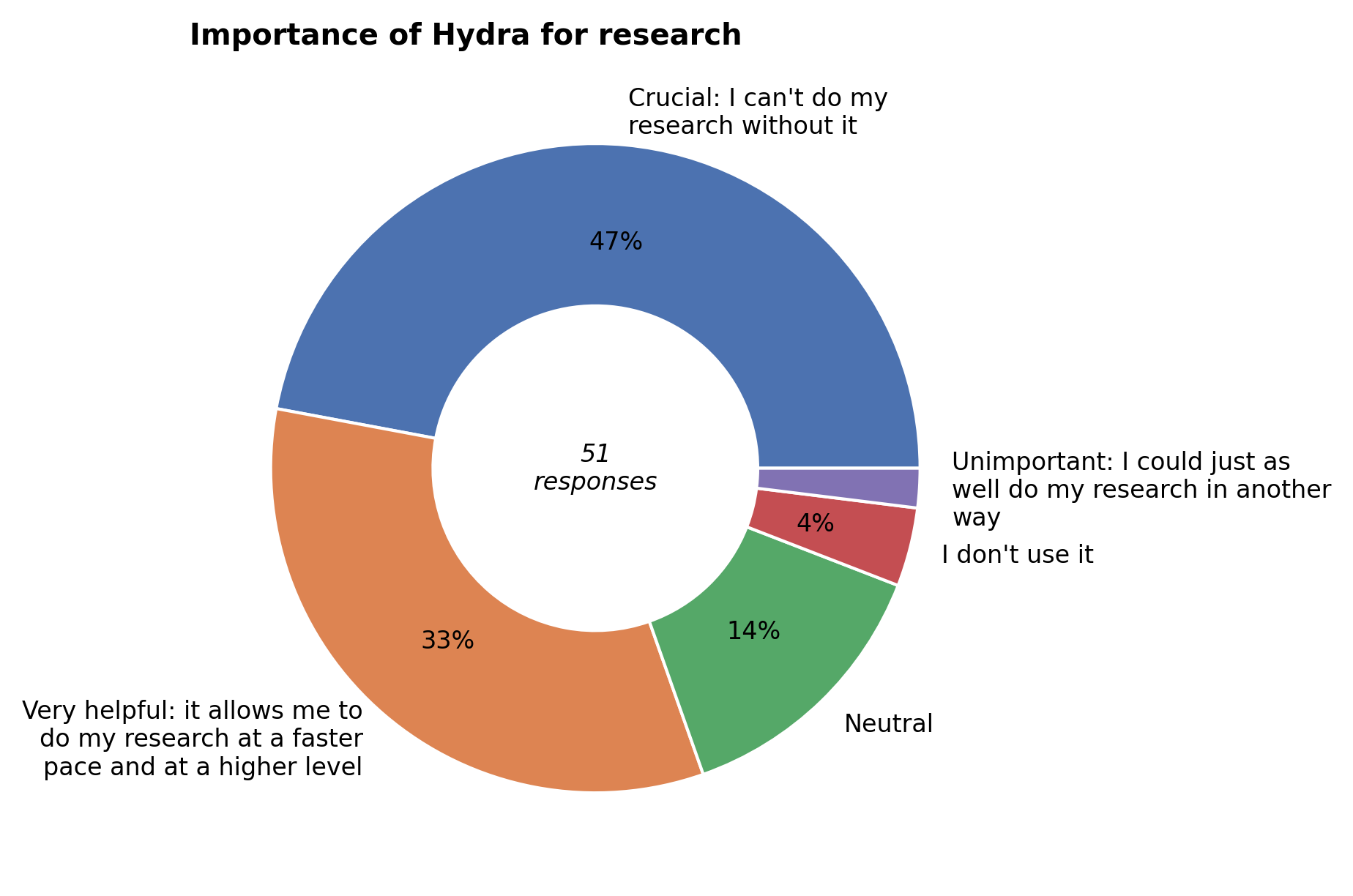
Importance of Hydra#
Hydra was rated very helpful to crucial for their research by 80% of respondents.
Overall rating#
Overall, all respondents rated VUB-HPC services as high to very high quality.
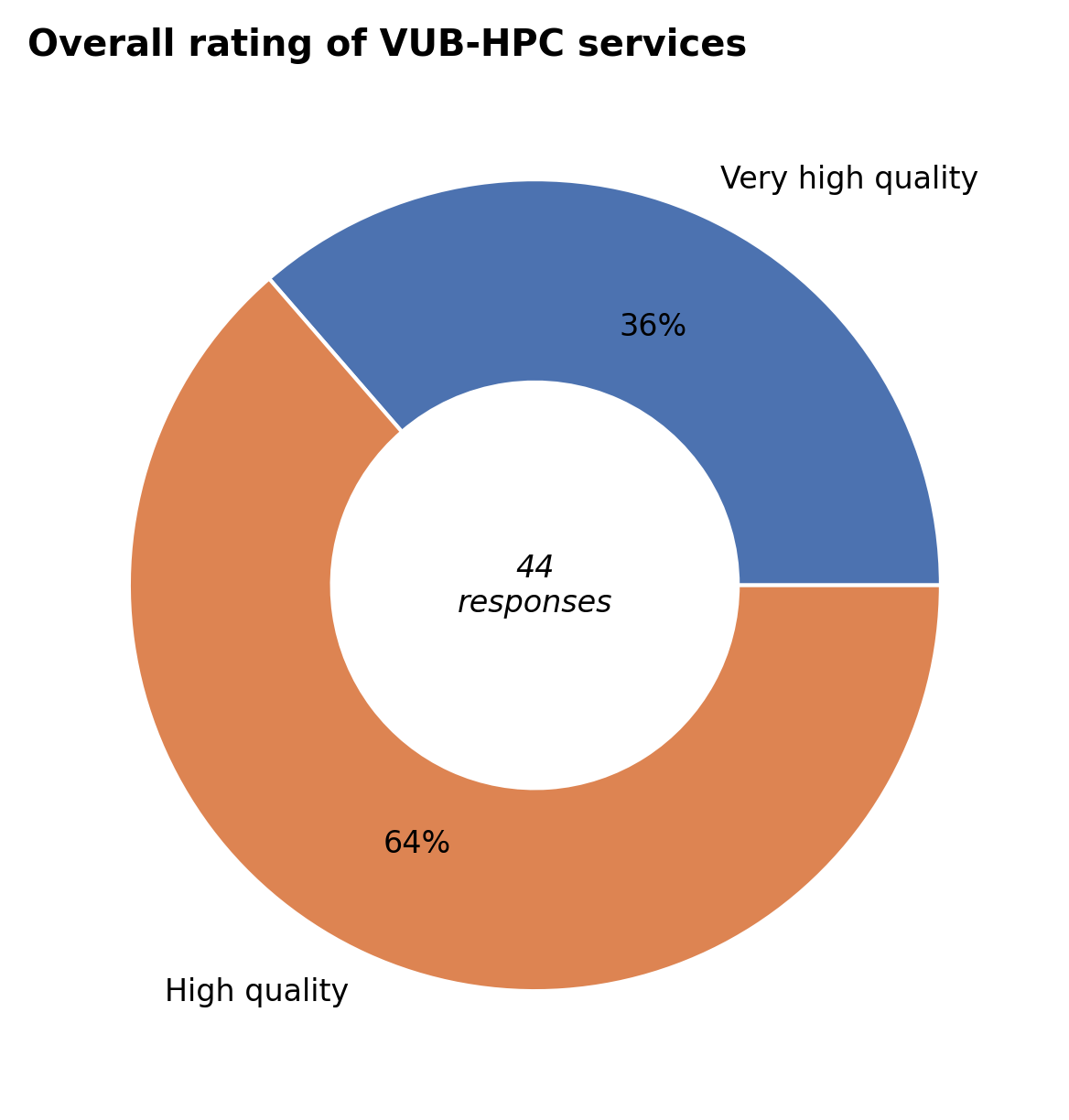
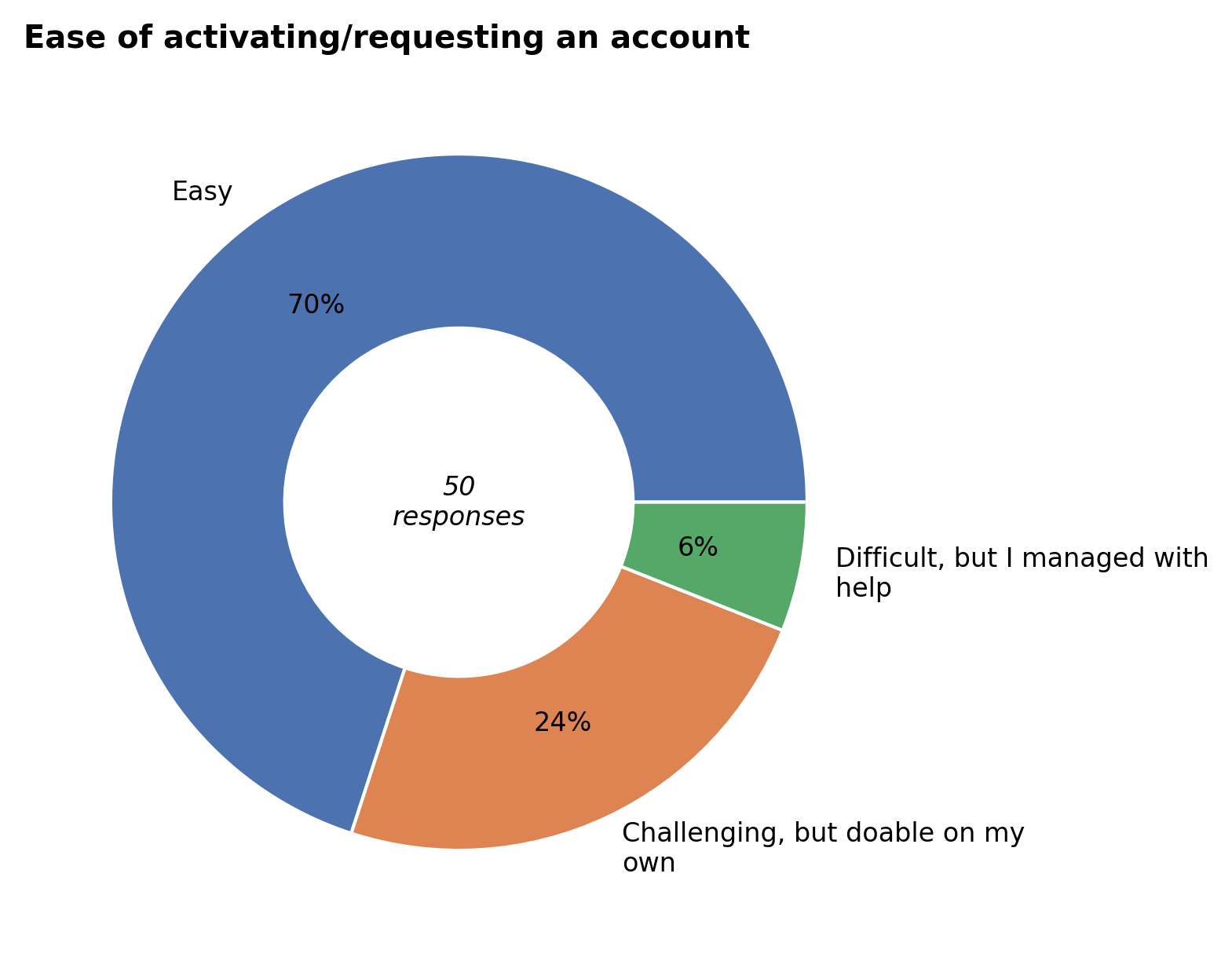
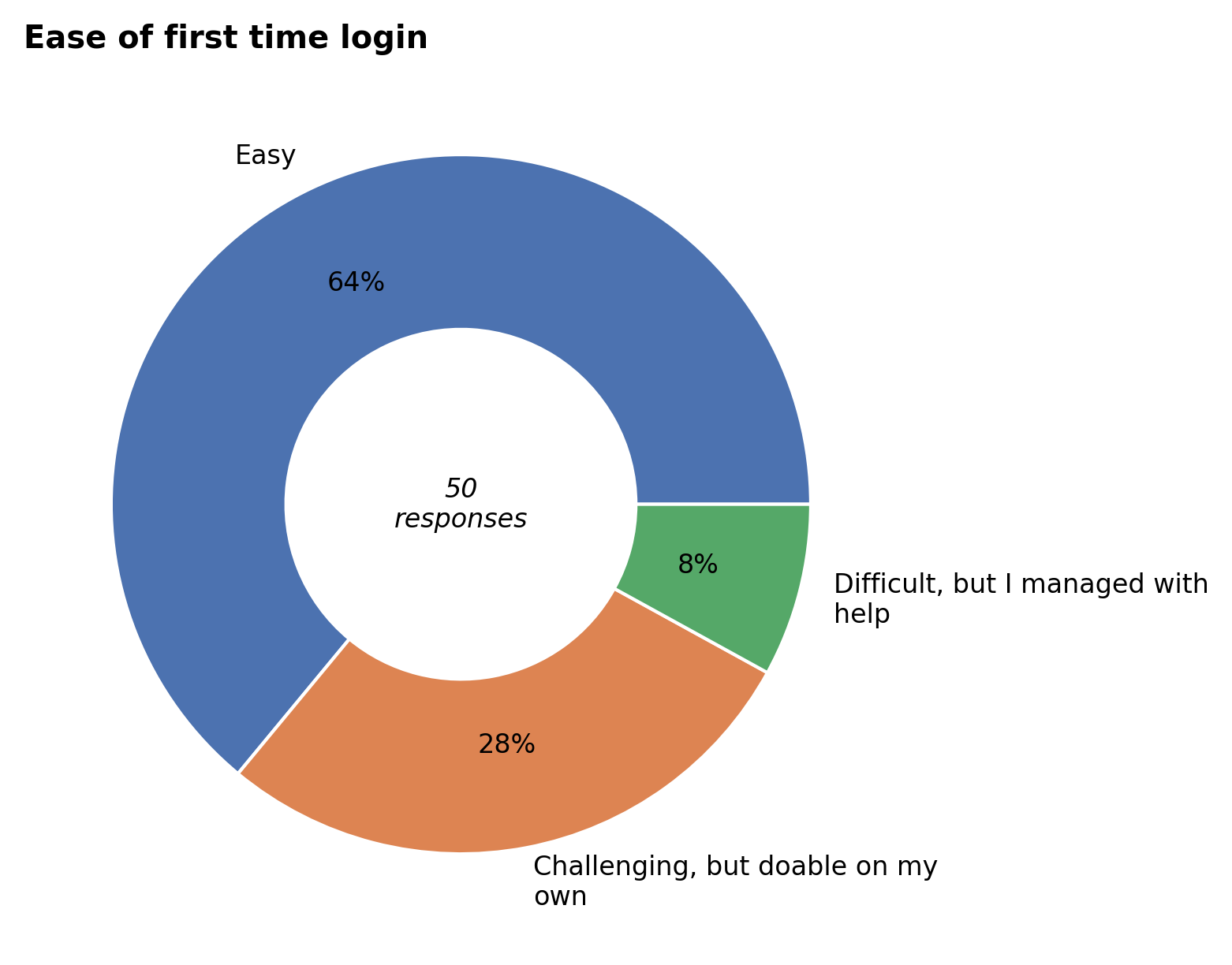
Getting access#
According to the respondents, creating a VSC account and login to Hydra was generally doable. Although the results are a bit better than last year, a considerable number of users still needed help to complete the process.
As a first step to address these difficulties, we have added an extensive connection checklist to help users troubleshoot their connection issues. We’re also working on a new web service for connecting to Hydra. This browser-based solution will eliminate the complexity of handling the account SSH keys by relying on the central VUB login for authentication.
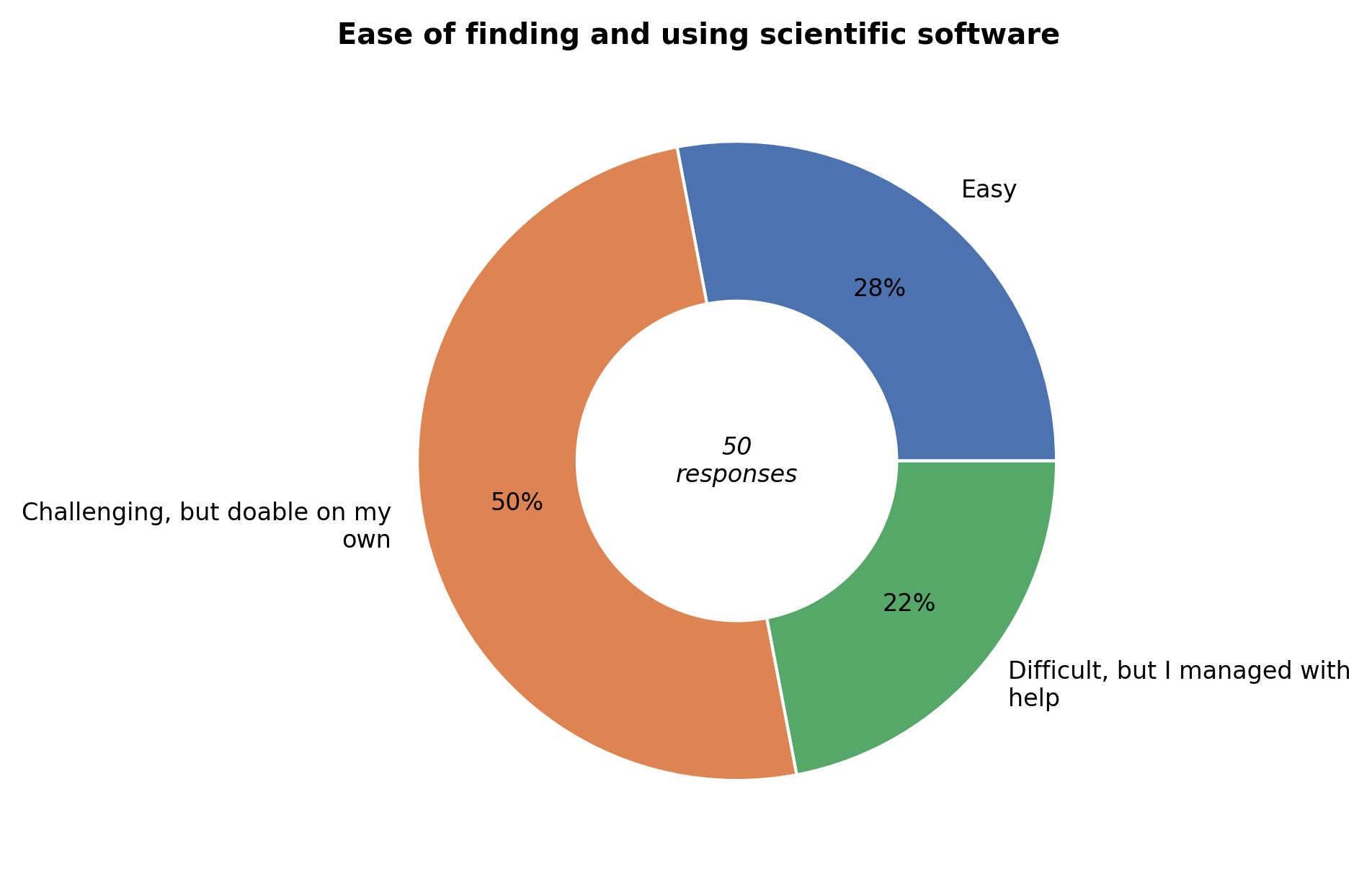
First time usage#
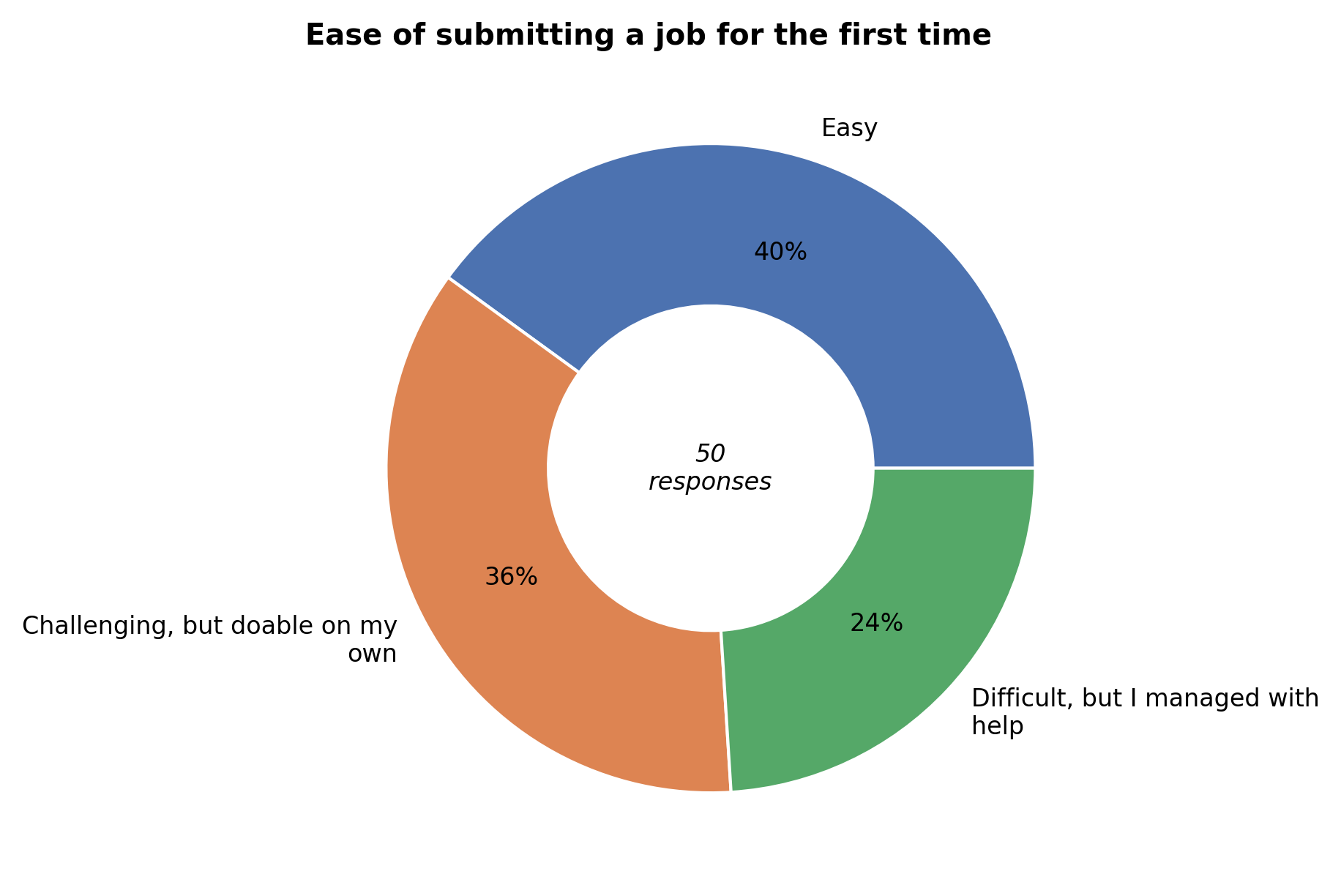
Finding software and submitting a job for the first time was doable for most respondents. Some users still needed help (22%), but markedly less than last year (47%). If you still need help, we kindly refer to the introductory training sessions (organized twice per year), training slides and accompanying videos, and friendly user support Helpdesk.
User support#
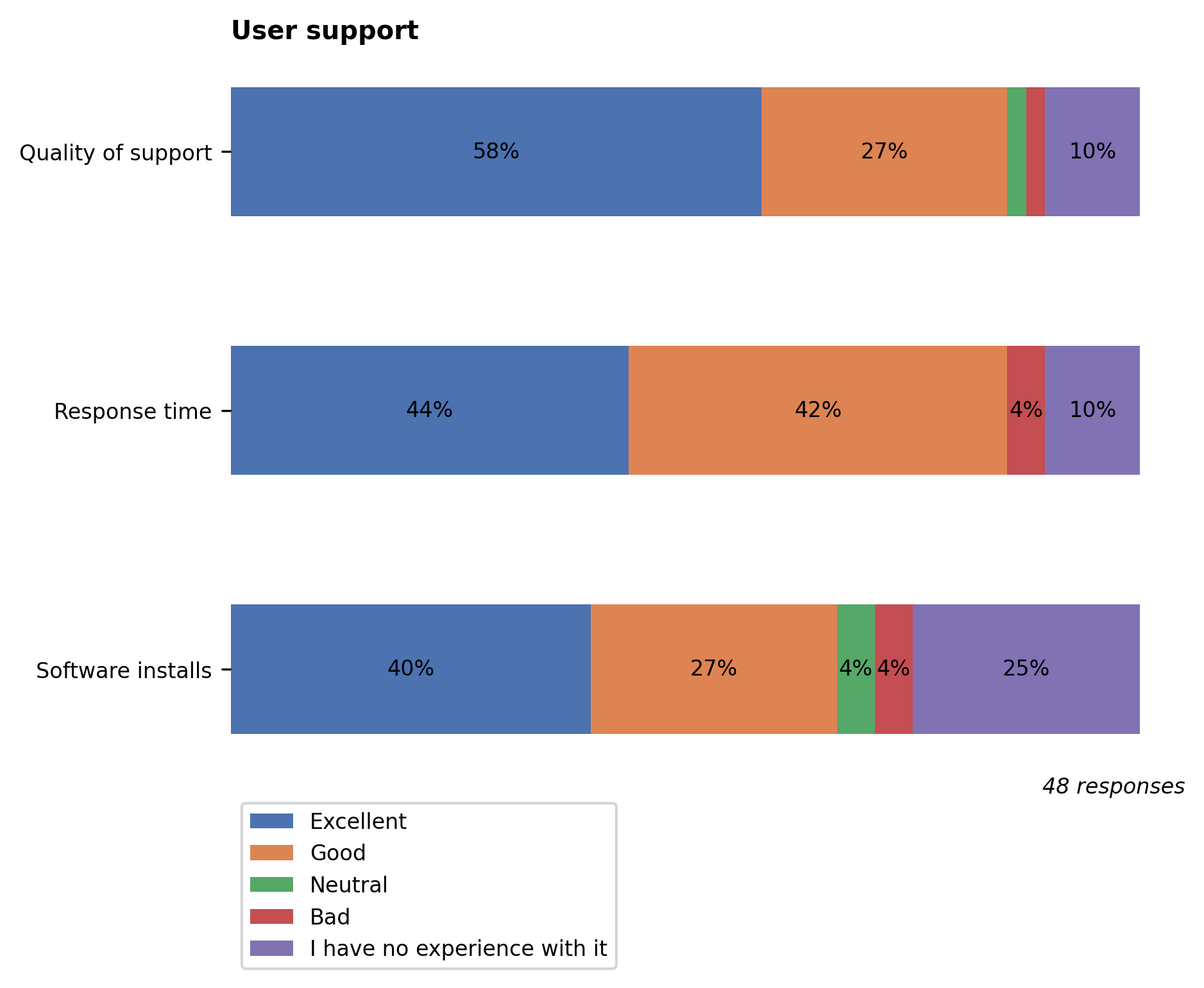
Most respondents rated the quality of support good or excellent, and those who made software installation requests were generally quite satisfied with our help.
Documentation#
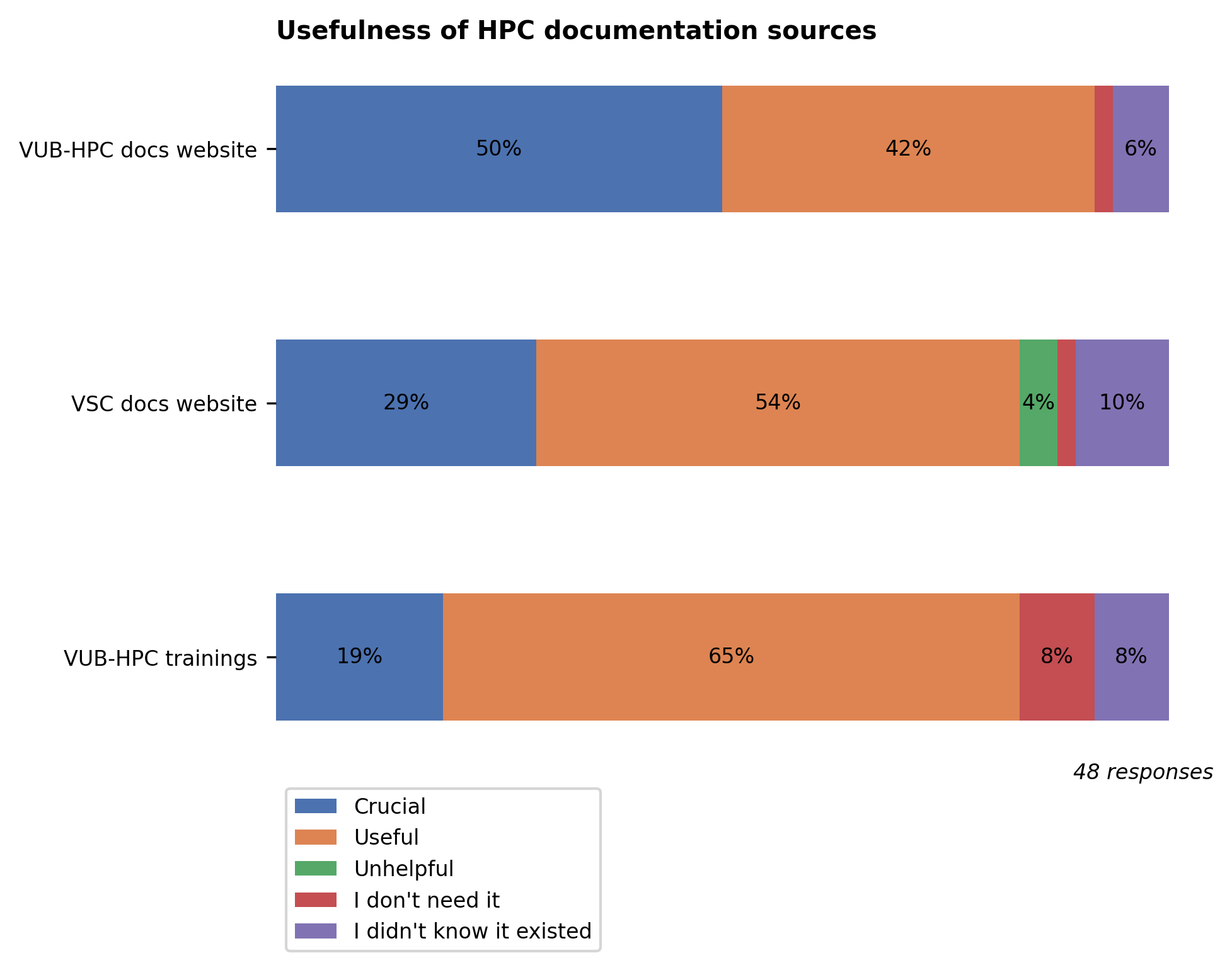
The documentation websites https://hpc.vub.be/documentation (Hydra-specific) and https://docs.vscentrum.be (general VSC), as well as the training sessions organized by the VUB-HPC team, are well known and mostly rated useful or crucial. Similar to last year, the VUB-HPC docs are valued slightly higher than the VSC docs because they are specific to Hydra and aimed at VUB users.
Communication#
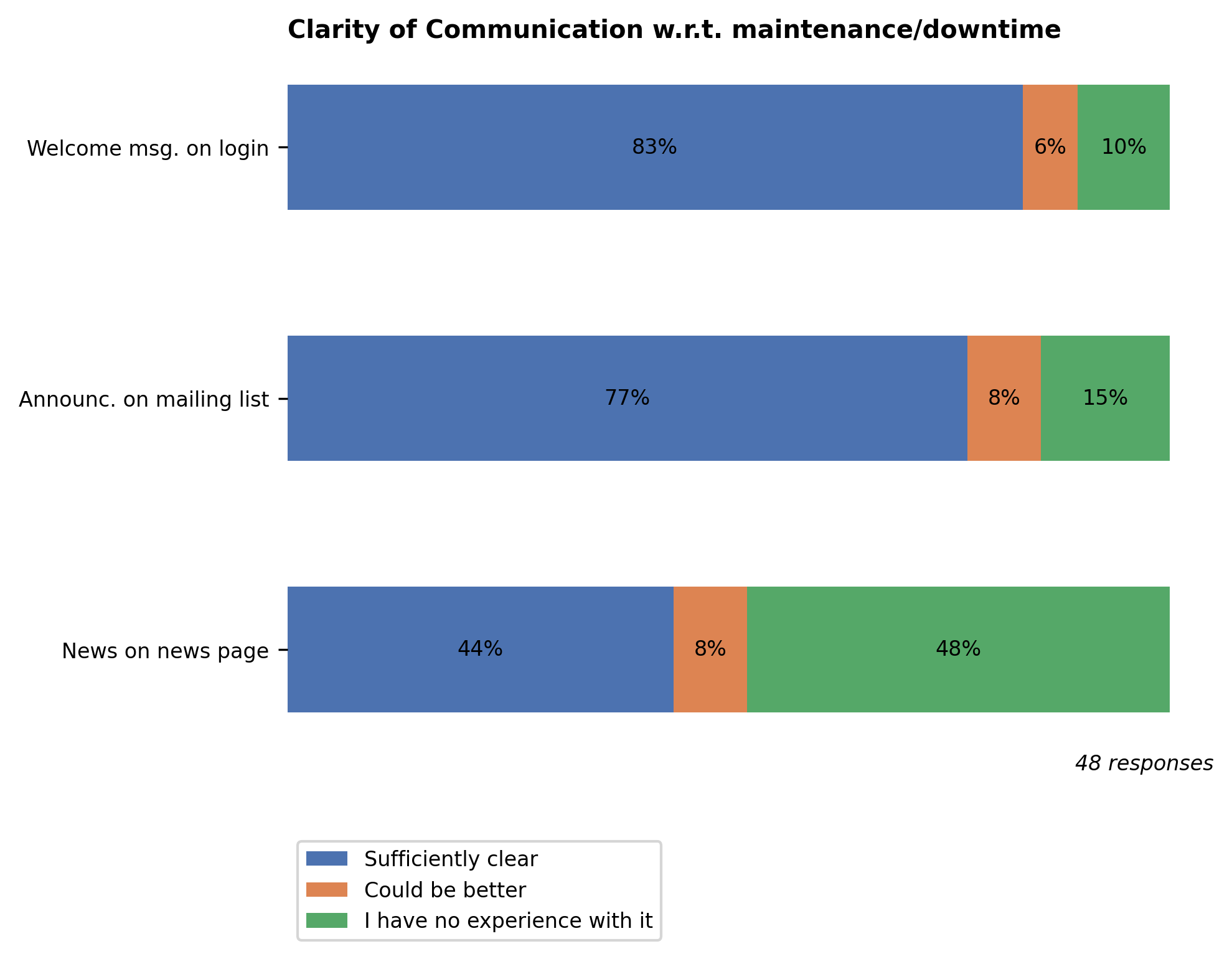
The welcome message upon login and the announcements in the mailing list remain the most important channels of communication to our users. As mentioned in last year’s survey report, we’ve moved the news items and events into the documentation site at https://hpc.vub.be. This move has payed off: 52% of respondents are aware of it, compared to 40% last year.
To further expand our reach in the VUB community, we’ve also started publishing all major news related to VUB-HPC on the WeAreVUB portal. To see the news items, make sure to check ‘HPC Scientific Computing’ in your settings >My job >Research & Innovation.
Software sources#
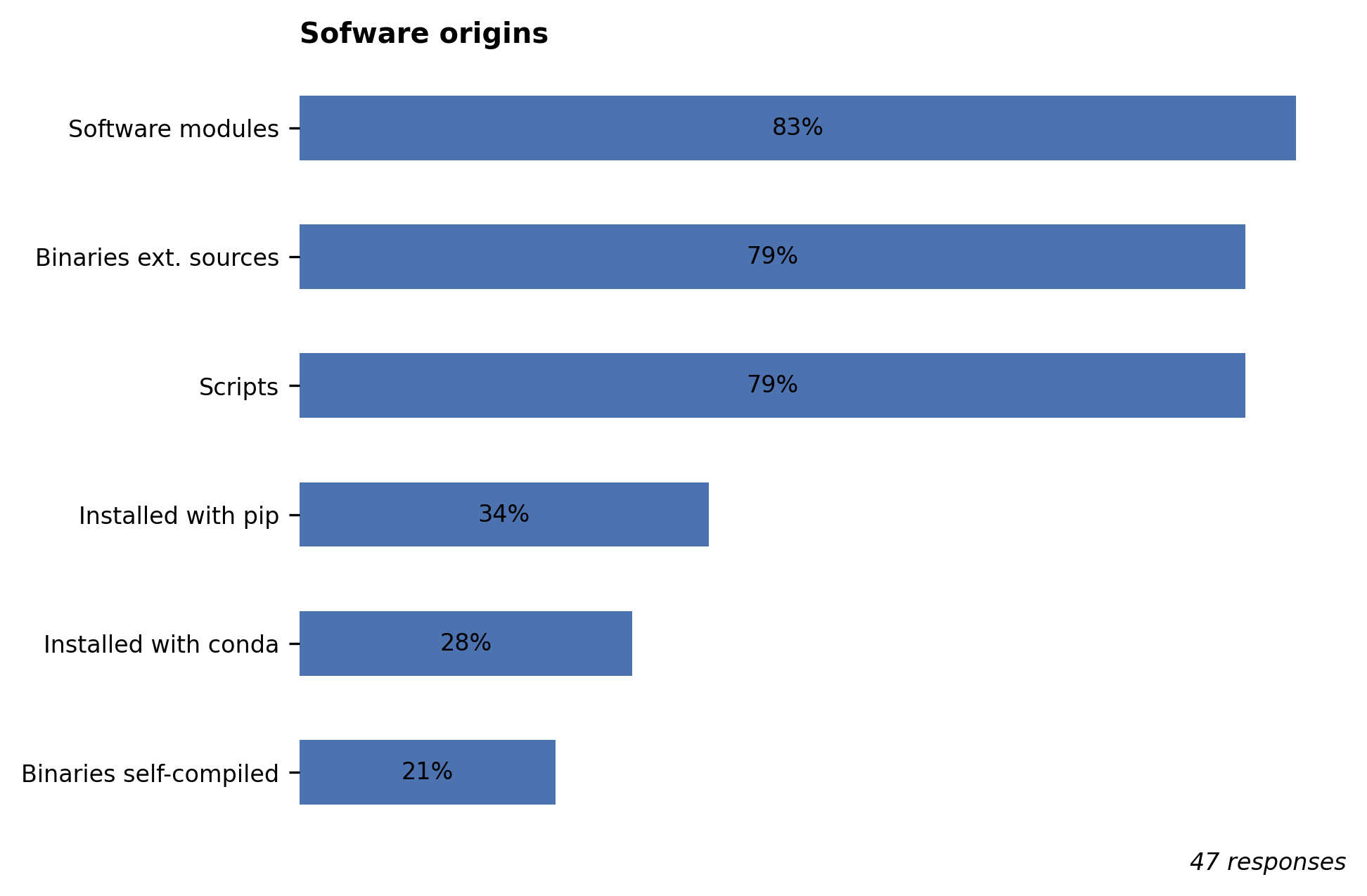
It’s gratifying to note that the software modules available in Hydra continue to be widely used, as the HPC team puts a lot of effort to make sure they run correctly and with optimal performance. However, we also note high usage of binaries from external sources. We generally do not recommend the use of external binaries as they are usually not optimized for the different CPU architectures available in Hydra. The same remark applies to conda and pip packages. If the sources are publicly available, we’ll be happy to build it and make it available as a module for you.
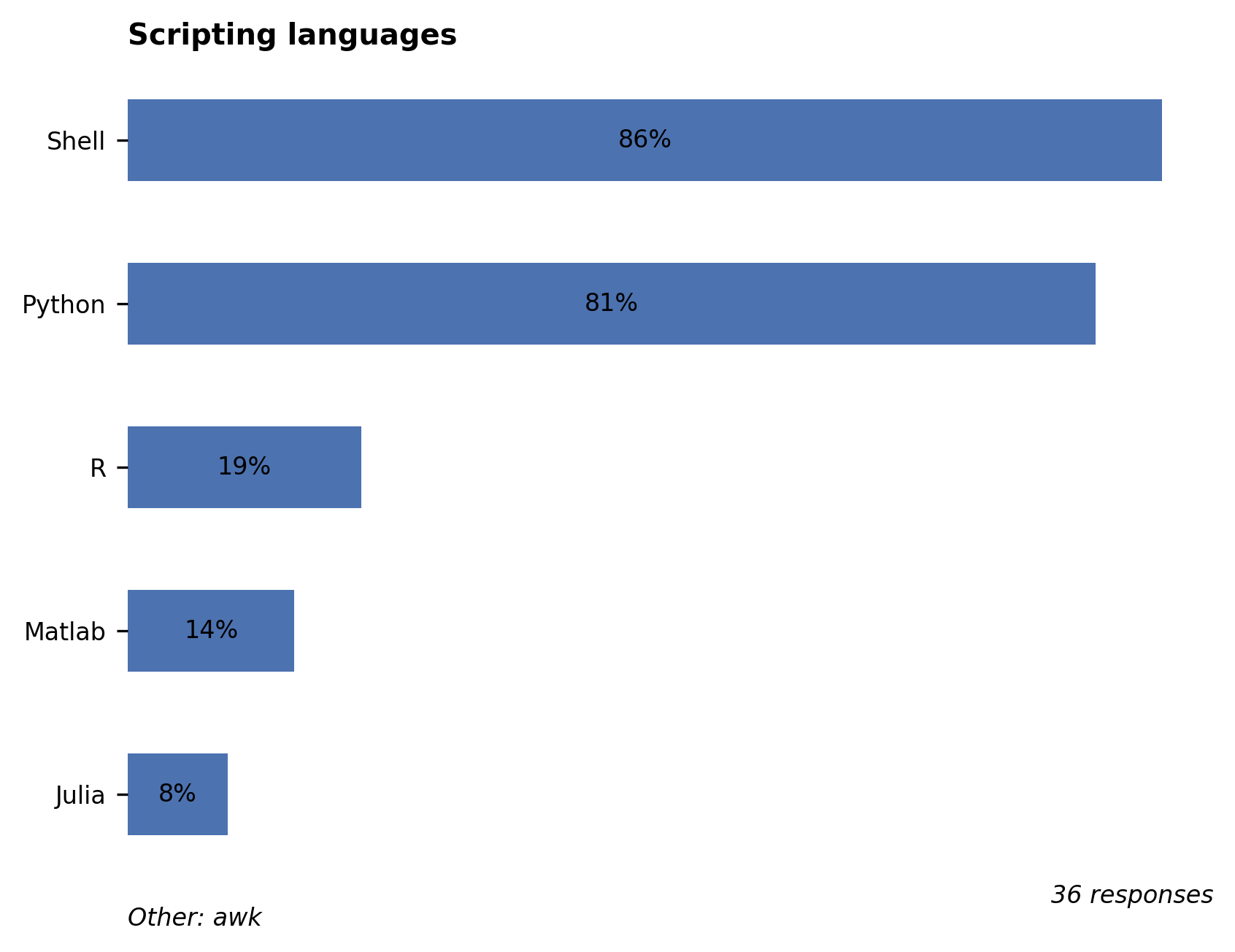
Aside from shell scripts (which are used to submit batch jobs), Python (81%) remains by far the top scripting language, followed R (19%). Many users still rely on Matlab (14%) as well, despite its lower overall performance. We recommend Matlab users to consider switching to Julia, a modern language with similar syntax and better performance. The Julia docs on noteworthy differences from Matlab may help you make the switch.
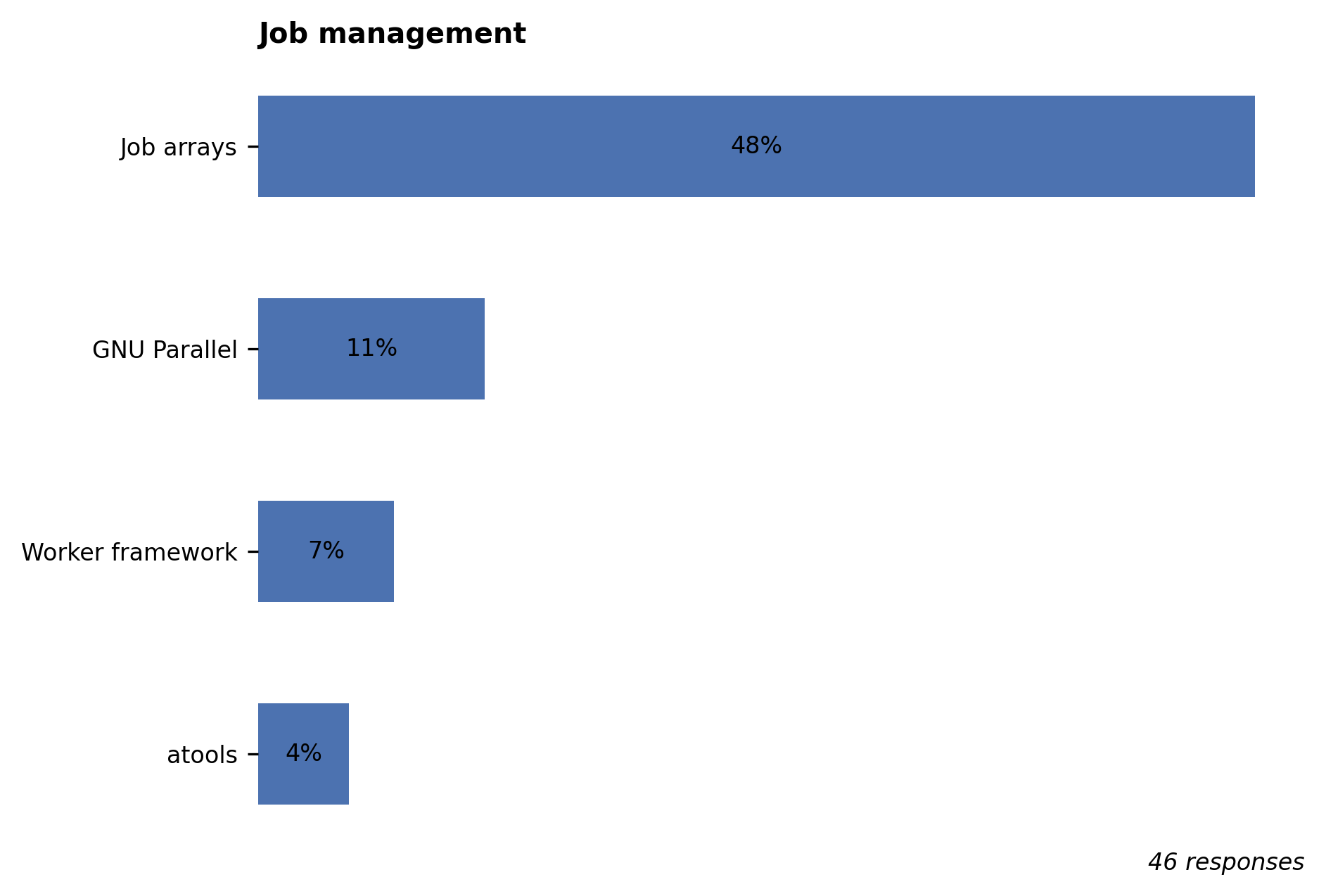
Job management#
We’re pleased to see job array tools (job arrays, atools) and task farming tools (GNU Parallel, Worker framework) showing up prominently in the survey. On the other hand, surprisingly none of the respondents indicated using a job workflow manager (such as Snakemake), despite it usefulness in creating efficient and reproducible scientific computing workflows. An example Snakemake workflow is available in our HPC training slides.
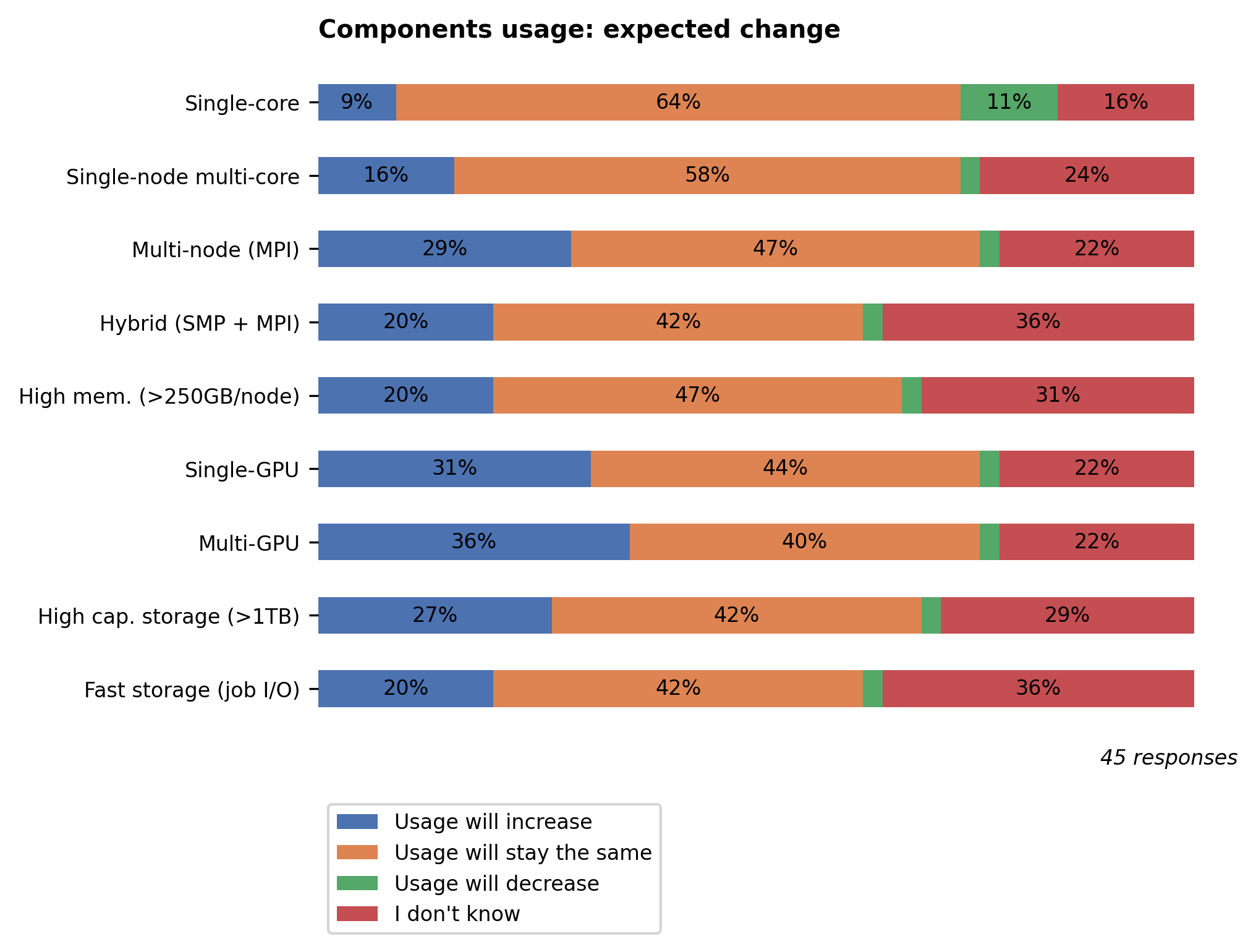
Components usage#
When asked how users expected their usage to change in the near future (1-2 years), the components that are most expected to see increased usage are GPUs (both single- and multi-GPU), multi-node (MPI), and high capacity storage.
Last year, 6 new nodes with 2x NVIDIA Ampere A100 GPUs have been added, and 2 more GPU nodes are expected to arrive in Q2 this year. Next to that, we’ve ordered a new scratch storage for Hydra, and a new self-hosted, secure, high-capacity VUB storage service is being installed.
Transition to Slurm#
For most respondents, switching to Slurm was trouble-free, and 20% of them even reported improved productivity with using Slurm.
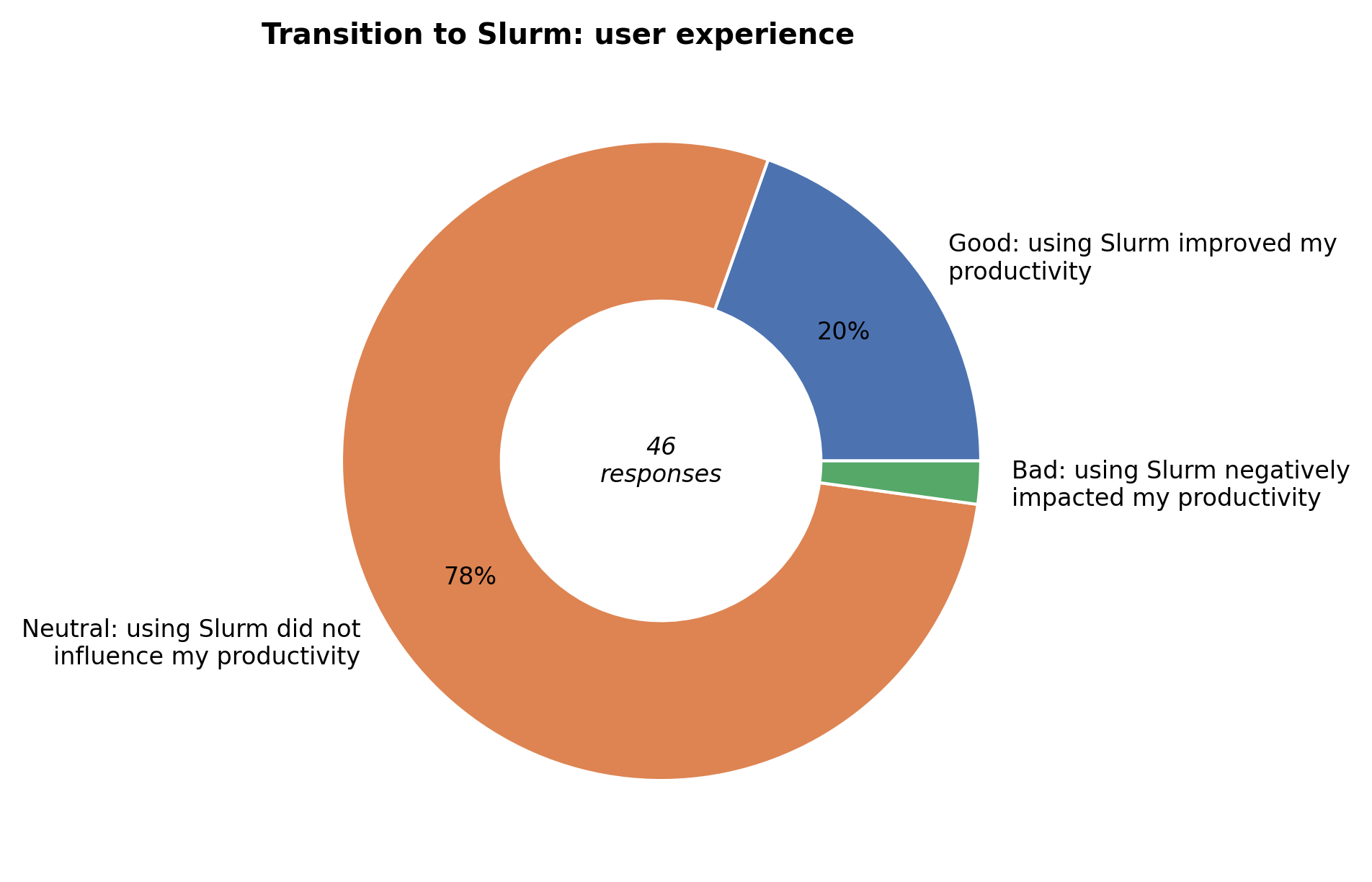
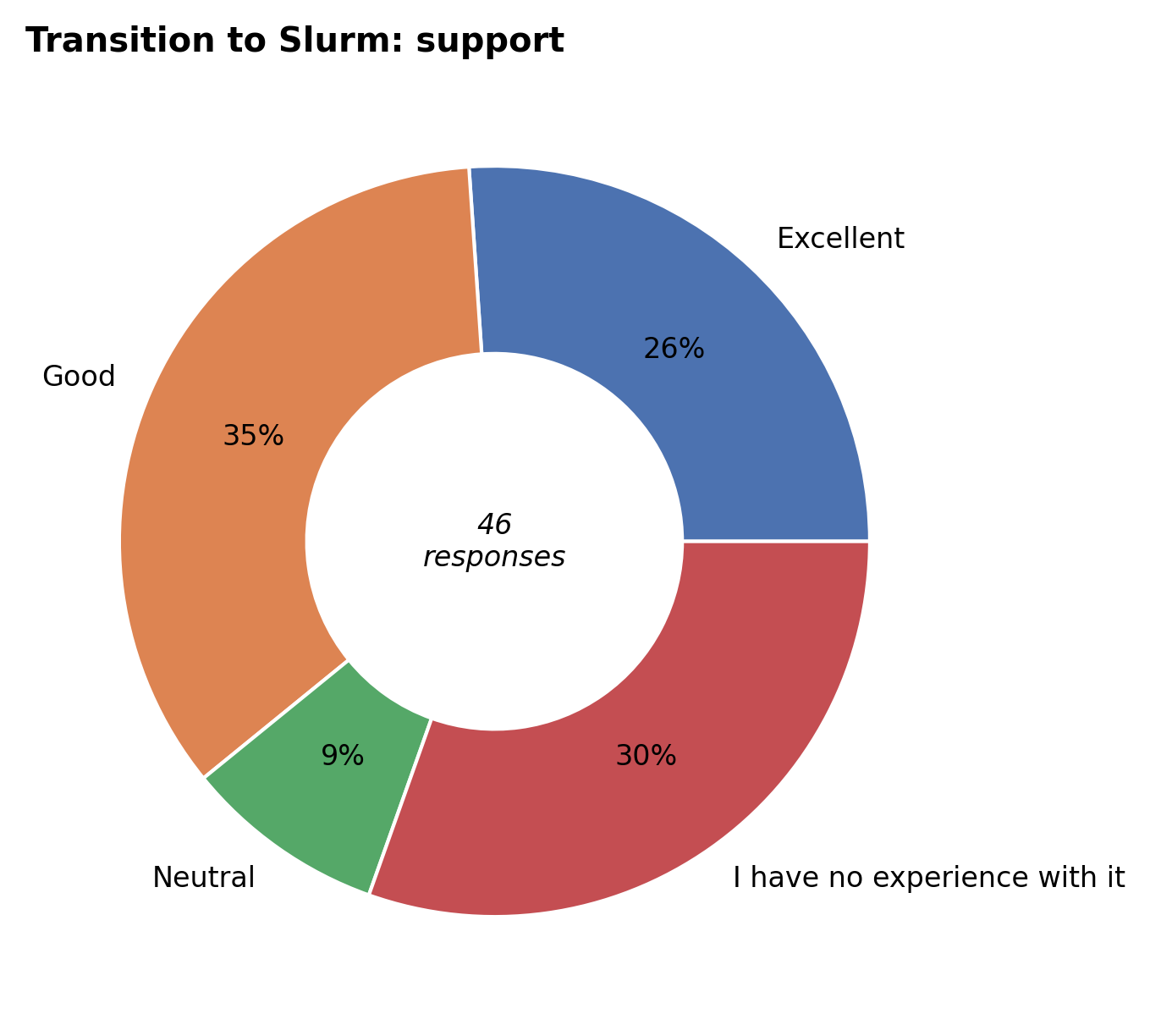
Users who needed help with the transition were generally happy with our support, either via our updated Slurm documentation and HPC training, special weekly Q&A sessions during the transition, or support tickets.
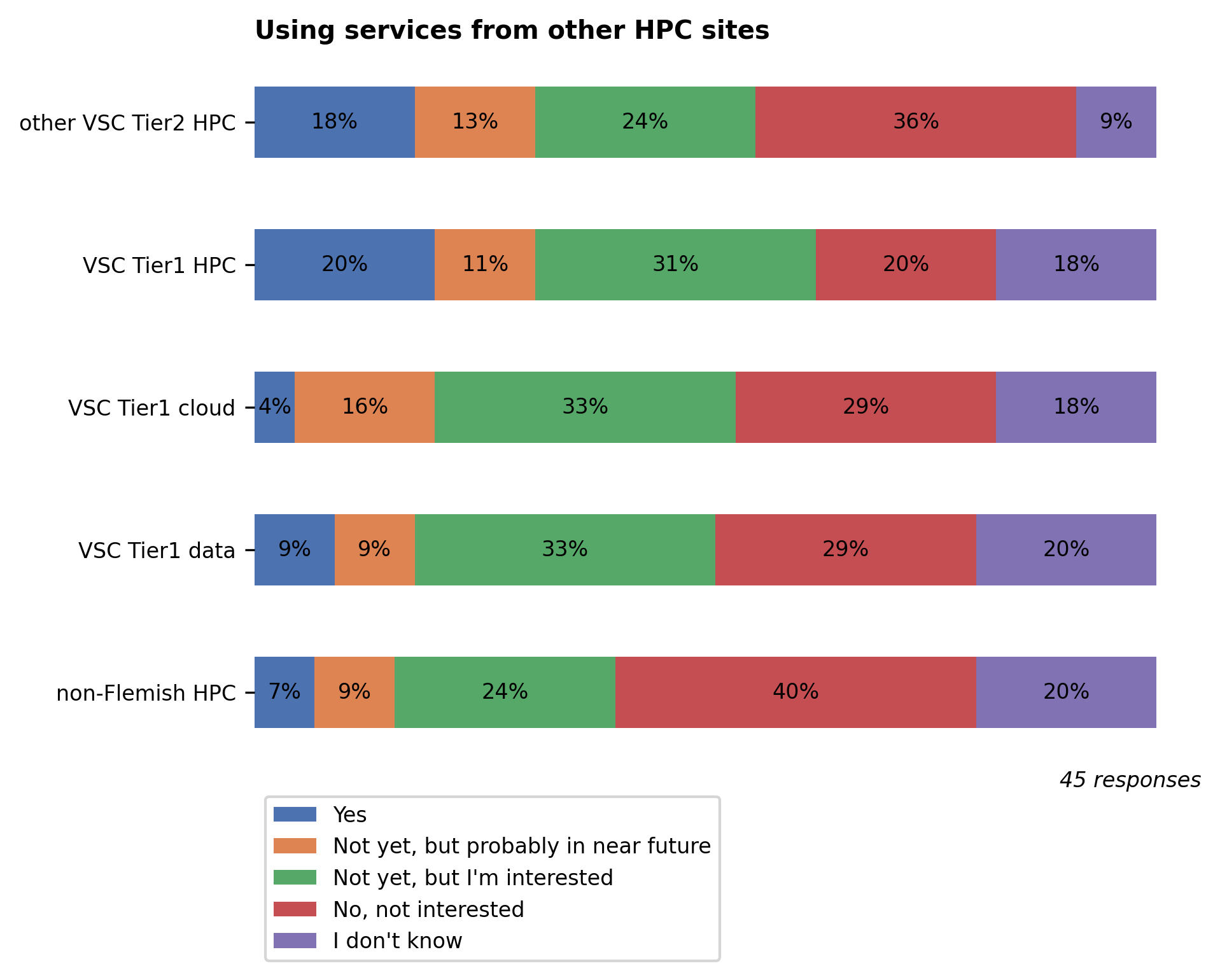
Usage of other HPC sites#
Usage of other VSC Tier2 HPC sites remains low, again highlighting the need to harmonize the user experience across the different VSC HPC sites. A working group has been formed within the VSC to hopefully bring improvements on this front.
The VSCwebVSC Tier1 cluster is free to all Flemish researchers upon approval of a project application, giving them vastly more compute resources than what’s available in Hydra. The new Tier1 cluster, Hortense, also has a large array of GPUs. Users who need large-scale compute resources, and who suffer long waiting times for their jobs, are encouraged to apply for a Tier1 project. To try it out and prepare a future regular Tier-1 project application, you can apply for a starting grant without too much hassle.
Analogous to Tier1 compute, the VSCwebVSC Tier1 cloud is free to all Flemish researchers upon approval of a project application. Users who need more flexible compute resources are encouraged to apply for a Tier1 cloud project.
The VSCwebVSC Tier1 data project, based on iRODS and Globus, is currently in pilot phase.
User requests/comments#
We also asked users if they had any comments or requests for specific documentation, technologies, or services that VUB-HPC does not yet provide. Below we briefly discuss the interesting ones.
- Documentation scattered over 3 places
The HPC documentation is indeed split over 2 sites (VUB-HPC docs and VSCdocVSC HPC docs) to avoid duplication. We acknowledge that this split can be confusing for users, all the more since VSC HPC docs contains a lot information that does not fully apply to Hydra. We will discuss potential solutions at the level of the VSC. In the mean time, users should treat the two sources of information as follows:
VUB-HPC docs: the main go-to documentation source for Hydra
VSCdocVSC HPC docs: should not be used directly; only follow the links to it in our VUB-HPC docs
The third source of information, the HPC training has a different purpose: practical training material for beginners with examples and excercises.
- Difficulty finding info on the different storage filesystems
This info was indeed hidden in the training slides. To fix this, we’ve added a new Data Storage section to our documentation.
- Jupyter notebooks
We’re happy to report that we’ve made much progress in implementing the new JupyterHub service that integrates with the Slurm scheduler in Hydra. We hope to announce more information soon. Stay tuned!
- Virtual environments more practical than the module system
For code development, using virtual environments can indeed be more practical. On the other hand, our software modules are optimized for performance, which is important for production runs. A good trade-off is a combination of both: using the software modules that are already available as a base and installing additional python packages on top (with
pip) in a virtual environment. To show how this can be done, we’ve added a new section in our documentation, see Python virtual environments.- Better handling of license renewal for Guroby
The Guroby license must be renewed every year, and users had to contact us when it was expired. From now on we will monitor the validity of the licenses to avoid this annoyance in the future.
- Tools for cluster status, when jobs will start, how to avoid wasting cpu/mem/walltime
Such tooling is indeed a bit lacking in Slurm at the moment. Monitoring resources usage can already be done in Slurm with
mysacct, but it is not as user friendly as the (now defunct) Torque-based toolmyresources. When time permits, we’ll add a similar Slurm-based tool, and also make available the amount of jobs in the queue. Getting an estimate when a job will start is already possible (via thesqueueoptions), but this value is not reliable, as it is impossible to know when running jobs will finish.